Understanding Infrastructure as Code (IaC)
What is Infrastructure as Code?
Infrastructure as code (IaC) means code written to manage or create infrastructure components, instead of managing the infrastructure manually by running imperative commands or by using a GUI. If you're not interested in the theory behind IaC you may be interested want to have a look at our introductory Terraform and Puppet articles instead.
Infrastructure as code brings all the tools of software development to system administration work, including version control, automated testing, change management and continuous delivery.
Manually managing infrastructure has several key issues which are represented in the adjacent table. Infrastructure as code tools solve most of the these problems. With IaC you often, but not always, have to spend more time upfront, but much less time debugging and fixing issues or coordinating work.

Benefits of Infrastructure as Code
Software development methods are a key enabler when building high-quality infrastructure. The diagram below shows an overview of the benefits that you can get with Infrastructure as Code:
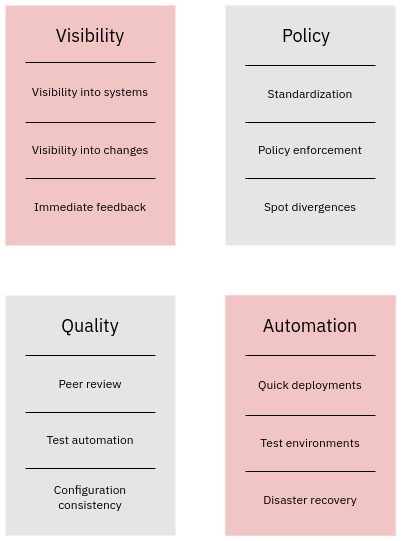
We describe these benefits in detail in the subsequent sections.
Visibility
Infrastructure as code provides you with up-to-date description of the desired state of your infrastructure. Moreover, as long as the code is deployed regularly, it also documents the current state of the infrastructure. You need this visibility into how things are now and how they would be when planning and making changes.
Now, contrast that with manually managed infrastructure, where visibility is mainly based on written documentation and the bits and piece of information various people have in their brains. Both of these types of information tend to be incomplete and/or outdated. These problems are compounded when the team responsible for infrastructure grows, as people have a tendency to solve the same challenges in their own unique ways. Therefore most of the time you need to actually go have a look to understand the current state of your infrastructure. The desired state, on other hand, is implicit and vaguely defined.
All this said the best visibility is gained with state-based infrastructure as code tools. This is because state-based code describes the actual desired state, whereas imperative code only describes the steps to reach the desired state. The latter are obviously less easy to read understand than the former.
Change management
If you have proper change management procedure in place you can apply quality controls and enforce policies on code changes. As such, the goal of change management is to improve the quality of changes you make.
Different types of changes
If you have proper change management procedure in place you can apply quality controls and enforce policies on code changes. As such, the goal of change management is to improve the quality of changes you make.
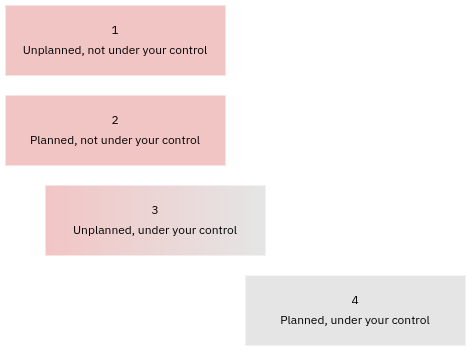
Here are some practical examples of changes types:
- Unplanned, not under your control: networking breakage at the ISP or the Cloud provider.
- Planned, not under your control: changes imposed on you by your Cloud provider, such as deprecating old versions of their SaaS products (e.g. AWS RDS engine version updates).
- Unplanned, under your control: out of memory (OOM) due to your server misconfiguration.
- Planned, under your control: all changes you have decided to make yourself.
Change management helps you reduce the number of unplanned changes, or incidents, in systems that are under your control (3). It accomplishes this by forcing changes to be planned (4).
Software quality assurance processes
A very efficient change management process for the changes that are under your control can be implemented with infrastructure as code. However, in practice, version control is required as well. All changes can and should go through standard software development quality assurance steps:
- Validation (syntax checking)
- Linting (style checking)
- Unit testing
- Acceptance testing (integration testing)
- Peer review
In the perfect world all changes would go through all of the above steps, but in practice this is not always viable. Validation and linting is usually directly supported by infrastructure as code tools and hence trivial to implement. Unit tests can be created if the IaC tool produces a machine-readable desired state which can be independently subjected to testing prior to deployment. Even when unit testing is possible (e.g. in case of Puppet), getting a good test coverage requires a significant time investment. Acceptance testing can be implemented for any tool, but it can end up taking lots of development resources to get it right.
The main goal of peer review is to catch issues that were not caught by automated systems. Review time should not be spend on issues that can be caught with automated tools such as validators and linters. Instead, the review should check if the changes do the right thing ("why") the right way ("how"):
While peer review is easy to implement technically, it may require a significant cultural change. If people don't understand why peer review is important, they are inclined to seeing it as a hindrance to "getting things done". This will inevitably reduce the time spent on review and hence their usefulness. Even when motivation for peer review exists, its usefulness depends on the quality of the review and reviewers:
A hastily done review by a junior who does not understand the context or the code is not of much value. A properly done review by a senior who understands what is being changed and why is of much, much higher value.
Automation
Infrastructure as code is essentially a machine-readable recipe which an IaC tool takes and consistently produces the infrastructure described in it. This alone provides a good basis for automation, as you can use the recipe as-is for disaster recovery purposes to recreate your environment as needed. However, in practice it is necessary to separate data from code to avoid infrastructure code tied to just one use-case.
Automation means automating a process that would otherwise be done manually. Automation in the context of Infrastructure as Code can be split into three main categories, configuration management, orchestration and event-driven automation.
Configuration management
Configuration management means automated configuration of systems. The systems can be baremetal systems, virtual machines, network switches, Cloud resources or applications. Configuration management is typically done with declarative infrastructure as code tools such a Puppet, Ansible or Terraform. These tools work by managing the configuration of individual components or resources, on the target systems. On Linux system the resources could be files, packages or services. In a Cloud context resources can be DNS records, load balancer listeners or security group rules. The state of the managed system is comprised of the state of all the managed resources. If any resources do not match the desired state, the configuration management system will automatically correct the situation:
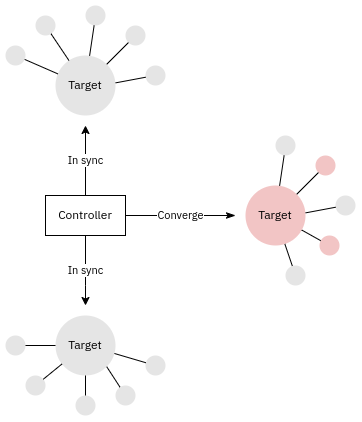
While containers and container images don't fit well into the classic configuration management paradigm, in reality the only difference is that they're usually baked whereas other systems are typically fried. These terms are explained in detail below.
Orchestration
Orchestration means automation of a process such as a software release or running tasks in response to an event. Often, but not necessarily, orchestration involves several systems and the order of events tends to be important. Here is an example of a classic non-containerized web application update process that illustrates the point:
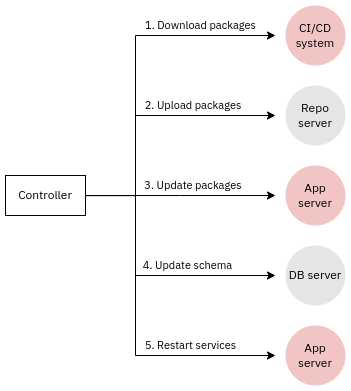
In a containerized context the CI/CD system typically has a much greater responsibility for ensuring that the entire process.
Orchestration tools include simplistic "SSH in a for loop" applications like Fabric or Capistrano as well as more advanced declarative tools like Puppet Bolt and Ansible. The latter are more suitable for tasks which require configuration management steps as part of the imperative orchestration process.
Event-driven automation
Event-driven automation is exactly what it says on the tin. For example an alert from a monitoring system could be used to trigger an automatic remediation process:
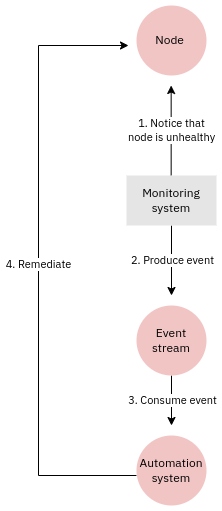
In this particular case there's no orchestrator or control node. Here various systems interact with each other to produce a desired workflow based on an event.
That said, any continuous delivery (CD) system is also an event driven automation system. The event in that case is a commit to a repository which triggers a build, automated tests and at the end a code deployment.
Standardization
It is much easier to achieve standardization with automation that without it. Standardization is tied with policies and policy enforcement that can be effectively enforced with change management procedures (see above). Standardization can mean many things in this context. A few examples:
- Using a standard operating system on desktop or server systems (e.g. Red Hat Enterprise Linux or Windows 11)
- Migrating all workloads to a public Cloud (e.g. AWS or Azure)
- Using certain application or application versions only
- Configuring all systems to authenticate users directly from Red Hat Identity Management with Kerberos or LDAP, or via Keycloak with OIDC or SAML 2.0 protocols.
Automation does not inevitably lead to standardization. However, standardization makes the automation process much easier:
- Fewer things need to be automated -> less automation code
- Less logic and conditionals are required in the automation code
Standardizing also improves the quality of automation code:
- Fewer corner-cases need to be tested
- Code paths are more thoroughly tested
- Scope of changes is easier to understand
What is declarative programming?
In declarative programming you define the desired state of the thing you are managing. This is unlike imperative programming where you define the steps your code will take. Many infrastructure as code tools are purely based on the declarative principle (Terraform, Puppet), some mix declarative and imperative (Ansible, Chef, Puppet Bolt) and some are purely imperative (Docker with Dockerfile).
Here's an example of creating a simple text file, first in the declarative Puppet language and then using imperative Linux shell commands:
file { '/tmp/foobar':
ensure => present,
content => 'foobar',
owner => joe,
group => joe,
mode => '0755',
}
$ echo -n foobar > /tmp/foobar
$ chown joe:joe /tmp/foobar
$ chmod 755 /tmp/foobarAs you can see, the declarative approach defines the desired state of the file, whereas imperative list the steps to reach the desired state. Similar comparisons can easily be made for, say, Terraform (declarative) and the AWS CLI (imperative). Purely declarative approaches are naturally idempotent, see below for details.
Under the hood even declarative IaC tools run imperative commands but this is hidden from the user of those tools.
Scope of the desired state
Infrastructure as code tools do not manage the complete state of the system, regardless of whether that system is a baremetal server, virtual machine or a container. Instead, they manage a subset of it. Anything not covered by the administrator-defined desired state is left alone. For example, on a Linux desktop system the vast majority of resources are not explicitly managed; instead their initial state comes from the operating system installation and is further changed by package upgrades and system services (logrotate, certbot, etc) as well as manual changes. Here's an example:
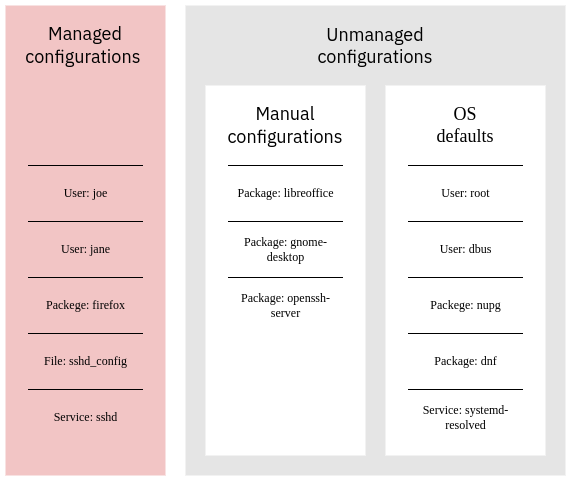
Containerization greatly reduces the likelihood of manual configurations, but does not have an impact on the operating system defaults. Every time you rebuild a container those defaults may change, e.g. due to security updates applied to the base image or by your container provisioning script (e.g. Dockerfile).
Similarly in the Cloud you always have a mix of unmanaged and managed resources. The former can be Cloud provider defaults or manual configurations. For example in AWS you could have something like this:
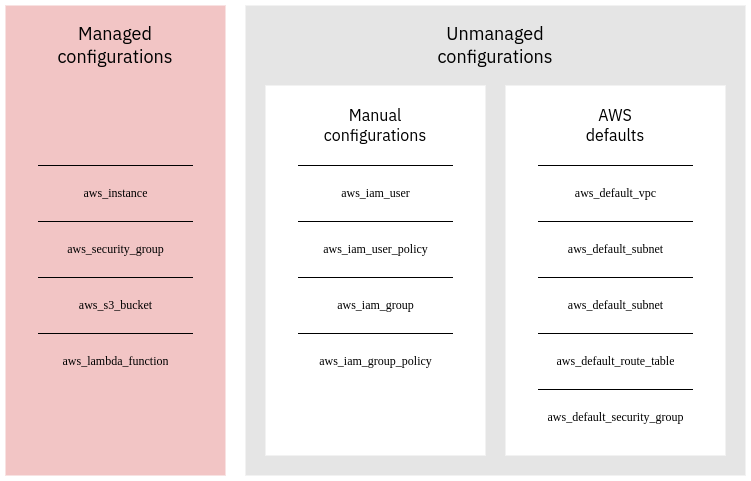
On top of this changes come from external systems. For example operating system updates change the state of the system outside of configuration management. Similarly Cloud providers occasionally change their defaults which may be reflected as unplanned changes in the managed resources.
What is idempotency?
A natural consequence of the declarative approach is being able to run the same code over and over again without any side-effects or changes to resources being managed. This feature is called idempotency. Here's an example of adding a line to a file, first with declarative Puppet code and then with imperative Linux shell commands:
file_line { 'myline':
ensure => present,
path => '/tmp/myfile',
line => 'myline', }
$
echo foobar >> /tmp/myfileIf you run the Puppet code again nothing will happen. When you run the shell command again, a new line is added every time. To solve this problem in shell you'd need to implement idempotency yourself with something like
#!/bin/sh
if ! grep -E '^foobar$' /tmp/myfile > /dev/null 2>&1; then
echo foobar >> /tmp/myfile
fi
The same principle applies to other declarative IaC tools like Terraform when you compare them to their imperative counterparts (e.g. the AWS CLI). The need to implement idempotency manually makes writing long, rerunnable and side-effect free scripts very laborious.
The only real alternative to implementing idempotency is to always build the thing you're managing from scratch, which is what Docker does when building ("baking") an image from a Dockerfile. Docker layers are just used to optimized the process, but the overall principle remains the same.
What is convergence?
Converge in the declarative configuration management context means doing the minimal steps required to bring the current state (reality) to match the desired state. In other words convergence fixes configuration drift, which is created by changes done outside of configuration management. Some of those changes are done manually, some by external tools (e.g. software updates) and some are side-effects of changes in default configurations (e.g. changes at the Cloud provider end). Here's a simplistic example of how convergence works in operating system level tools such as Puppet:
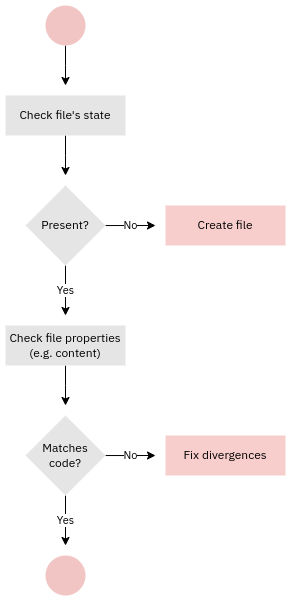
The terms convergence and configuration drift are important for mutable infrastructure but not for immutable infrastructure.
What is mutable and immutable infrastructure?
If a system's configuration is supposed to be changed over its lifecycle the system is considered mutable. If a system is rebuilt on every configuration change then it is considered immutable. Immutability is rarely absolute, but rebuilding on every configuration change reduces the likelihood of configuration drift and any configuration drift will be corrected much faster. The terms mutable and immutable are closely linked with to two main ways of building and maintaining infrastructure: frying and baking.
What are frying and baking?
Managing the configuration of system over its lifecycle aims to correct configuration drift. This process is sometimes called frying, which refers to a typical cooking process where you start frying something in a pan, then add more ingredients, then fry some more and finally, when the dish is ready you eat it. Similarly when managing a system you first make changes to reach the initial desired state, then periodically make changes over the lifetime of the system until its reached its end of life and you destroy it. Physical computers and virtual machines are often fried. In other words, you set up the initial state of the system and then change it as needed until the system is ready be decommissioned.
The term "baking" derives from the way you would bake a cake: you prepare the dough, put the dough into the oven, wait a while and finally take the finished cake out. When managing a system this means that you create ("bake") a new instance of the system from scratch every time there's a configuration change.
The diagram below illustrates the differences between baking and frying:
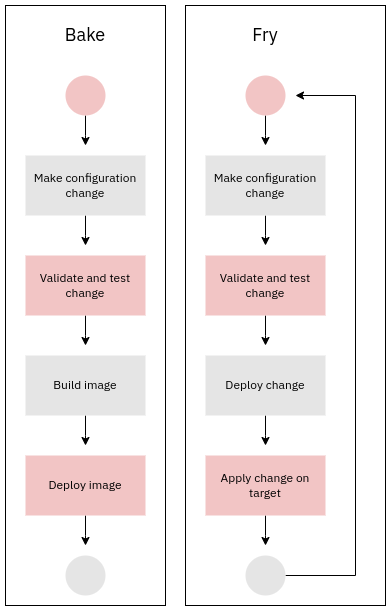
As can be seen from the diagram, the main difference is that frying operates on the same system, whereas baking creates a new system from scratch. In frying the lifecycle of the system is typically long, whereas in baking it is typically short.
There are several example of systems used for baking:
- Building Docker container images
- Building golden images of physical computers (e.g. with FOG)
- Creating pre-configured, auto-deployable VMs (e.g. with Packer for use with Cloud marketplaces or EC2 auto-scaling groups)
- Installing and configuring operating systems with Autounattend.xml, kickstart, preseed, or autoinstallation
Traditional configuration management tools like Puppet, Ansible, Chef and Salt are used to fry a system, in other words manage the system over its lifecycle with incremental changes.
In practice both bake and fry methods are often mixed together. For example:
- You create a Windows system from a golden image with FOG and then install some user- or department-specific applications on top
- You install a Red Hat operating system and configure a configuration management agent with kickstart. After installation you let a configuration management system take control over the system.
- You launch a VM baked by somebody else (e.g. Microsoft, Red Hat) in a public Cloud, then use your own provisioning and/or configuration management scripts to configure it.
What are push and pull models?
Infrastructure as code tools apply their configurations by pushing them to the managed systems, or by letting the managed systems themselves pull and apply the configurations. The diagram below illustrates the concepts:
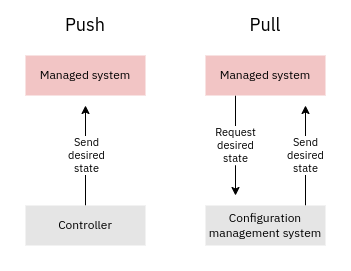
IaC tools that use the pull model often have an agent running that polls a configuration management server for the latest desired state. If the current state does not match the desired state then the agent takes corrective action. This means that in a pull model the agent is effectively a continuous delivery system. The pull model is best suited for with mutable (fried) infrastructure and is can be utlized when you have full access to the systems you're managing. Baremetal desktops and virtual machines are good examples of such systems.
Tools that utilize the push model work differently. They are launched from a controller, which could be your own laptop or a CI/CD system like Jenkins. If the tool in question is declarative the controller reaches out to the systems being managed, then figures out the differences between desired state and current state and runs the commands required to reach the desired state. If the tool is imperative controller just runs commands it is told to or deploys a new pre-baked image. In any case the target systems do not need a dedicated agent to be running. The push model is often only choice when you only have limited (e.g. API) access to the system you're managing: this is the case with public Clouds and SaaS for example.
Infrastructure as code tools can be grouped into the pull and push categories:
- Puppet server + agents (pure pull model over TLS)
- Puppet Bolt (pure push model over SSH or WinRM)
- Masterless Puppet over Git (pull model over SSH or other Git-compatible protocol)
- Ansible (pure push model over SSH or WinRM)
- Controller-less Ansible over Git (pull model over SSH or other Git-compatible protocol)
- Terraform (pure push model over various APIs)
- Deploying Docker containers using a CI/CD system (pure push model)
As can be seen from these examples only Terraform is a purely push model tool. This design choice was forced over it, though, because most of the systems it manages are only available through APIs.
In practice pull and push can be combined. For example, some Puppet providers use API calls to push changes to a remote or a local system. Yet those API calls might be triggered by a Puppet Agent that pulls it configurations from a puppetserver.
Separation of data and code
Data and code
When you install a new application to your computer you often have to configure it. In this scenario the configuration is your data and the application is the code. For example, the WiFi networks you have saved are specific to you, that is your data. The application that connects to those networks is the code.
Other typical examples of data are usernames, passwords, tokens, Cloud provider regions, memory allocation configurations, operating system versions and VM instance types. Some data like passwords and tokens are by their nature sensitive, and while only a savage would commit secrets to version control unencrypted, some do. Data can be thought of as the environment-specific part of the code. Data is usually passed as input or environment variables to your infrastructure code to fine-tune how the code behaves.
Few would propose mixing data and code, especially in software that
- Is distributed to others
- Needs to adapt to different use-cases
The same principle applies to infrastructure as code. You want to keep data and code separate to support differences between
- Development stages (production, staging, development)
- Geographic locations
- Deployment scenarios
- Operating systems
- Policies
The diagram below illustrates the "development stages" use-case for separating data and code in a typical web application deployment context:
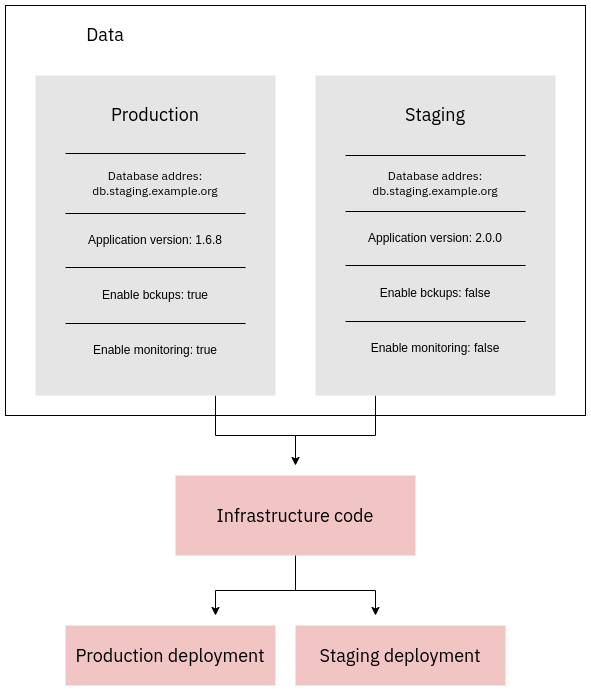
Modularization
Separation of data and code can be augmented with code modularization. Its end result is a reusable piece of code. Its exact depends on the IaC tool, but here are some examples:
- Puppet: module
- Terraform: module
- Ansible: role
- Docker: image
- Podman: image
From now on I'll just use the generic term module for simplicity. A module takes data in form of variables and uses that to fine-tune what the module does. If changing variables is not enough to create the desired behavior, then code changes are also needed.Suppose you have three different infrastructure as code projects which have different reusability levels.
Example: levels of data and code separation
Now that we've explained the terms data, code and modularization, let's move to an example. Suppose there are three infrastructure as code projects with different levels of separation between data and code:
- Data is stored in the code
- Data and code are separate
- Data and code are separate, code has been modularized
Project 1 has no seperation between data and code. This is usually a bad security practice, but it also prevents the code from being reusable. For example, you can't use the code as-is to create a production/staging environments or a blue/green environments. You could copy-and-paste the code and change the data, but then you'd end up having to fix the same issues in multiple places. This would result in a maintenance nightmare eventually.
In project 2 you have separated data and code. With this approach you can easily create almost identical environments by simply by passing the differences as data to your infrastructure code. You also don't need to commit secrets to version control. That said, the codebase may still contain lots of code shippets that are very similar and are basically copied and pasted around.
In project 3 you've taken things one step further. You've separated data from code. Moreover, you have identified commonly repeating code snippets and converted them into reusable modules. Data is passed to the modules and from there to the code. This reduces the need to repeat code further, making the code highly reusable.
