What Is Puppet and How Does It Work
What is Puppet?
Puppet is a convergence-based, push- and pull model "infrastructure as code" (IaC) tool that uses the declarative Puppet language to describe the desired state of the infrastructure. The systems that Puppet manages are in general mutable, meaning that you manage their configuration over their entire lifecycle instead of rebuilding them from scratch on every configuration change, like you'd do with Docker containers, for example. Puppet is mainly, but not exclusively, used to manage *NIX and Windows on the operating system level.
All these terms are explained in our Understanding Infrastructure as Code article which is highly recommended if don't already have a moderate amount of IaC experience.

R10k is started on Puppet master. It's going to get a branch ("production" or a feature branch) from the Git repository. (A scene from the Puppeteers Duplo series)
Puppet operating modes
Puppet supports several operating modes based on the push and pull models. Below we described the most common ones, but there other variants are possible.
Puppet server with Puppet Agents
Traditional pull-based Puppet deployment consists of one or more Puppet servers and one Puppet agent on each system (node) being managed. The agents poll the servers to fetch the latest desired state as a catalog for the node they're running on. If there is any divergence from the desired state (e.g. package not installed, file contents wrong) then the agent that runs with root privileges fixes the situation. The agent-server setup is often coupled with PuppetDB. PuppetDB is essentially a data warehouse for Puppet data such as reports and facts from agents. This data can then used for integration tasks using exported resources or queried using the PQL language.
Here is an overview of the usual Puppet agent-server architecture with PuppetDB:
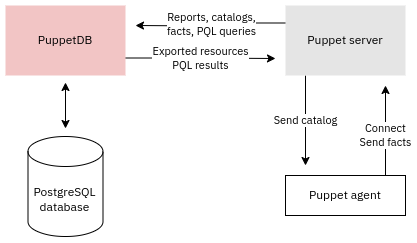
There are several benefits for the server-agent architecture including, but not limited to:
- Continuous delivery of configuration changes without a dedicated CI/CD system
- Continuous policy enforcement: agents enforce that systems are compliant with defined policies
- Reliable TLS transport: no need to worry about host key or known_hosts issues that SSH has
- Managed nodes only have access to their own code
- Scales well to thousands of managed nodes
The downside is that you need to install a dedicated agent on every managed node.
Serverless Puppet
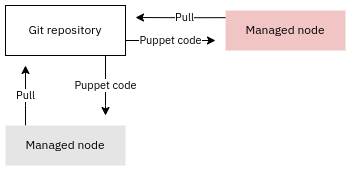
Puppet Bolt
The third way to deploy Puppet is to use Puppet Bolt, which is an orchestration tool that can easily handle configuration management tasks as well: this makes its use-cases and scope very similar to that of Ansible. Like Ansible Bolt uses the push model to apply configuration. When using Bolt for configuration management the catalog (desired state) is compiled on the Bolt controller and copied to the nodes being managed. Puppet is automatically installed to a temporary location on the managed nodes after which they are able to apply the uploaded code locally:
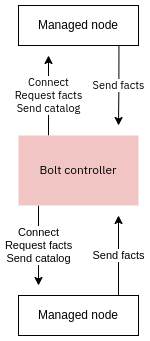
Local puppet apply
The simplest way to use Puppet is to apply local code with "puppet apply". This is essentially the same approach as serverless Puppet, with the difference that there's no remote version control repository to pull code from. The use-case is different as well: the goal is not so much to manage something as to build something. This mode is therefore very useful for provisioning images with Packer and virtual machines with Vagrant. In fact, we use "puppet apply" quite extensively in our Puppet modules.
How does Puppet work?
Enforcement of the desired state
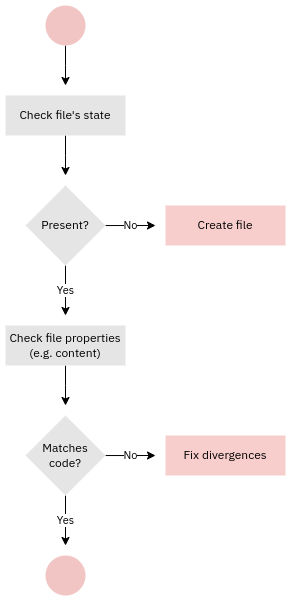
The catalog is the aggregation of the desired state of all the resources managed on the node.
The responsibility for compiling the catalog depends on Puppet's operating mode:
- In a server-agent operating mode it is the responsibility of the Puppet server to compile the catalog for the agent.
- With "puppet apply" the local Puppet installation compiles the catalog as well as applies it
- With Puppet Bolt the controller compiles catalog, copies it to the managed node where the it gets applied by a local Puppet installation.
Use of facts
Facts are an integral part in Puppet and other configuration management systems like Ansible. They are essentially pieces of information about a system, for example:
- Hostname
- Fully-qualified domain name
- Operating system family
- Amount of memory
- EC2 instance type
These can be used in code and data to drive conditional logic or to populate template files. They are also used internally by Puppet to select the default providers to use:
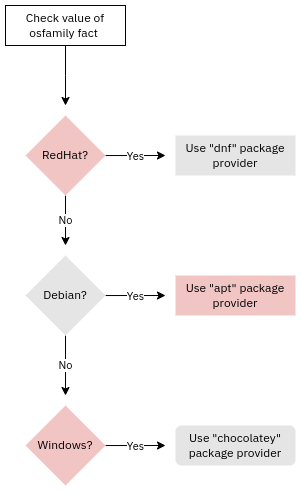
Separation of data from code
Puppet allows clean separation of data from code with Hiera. The diagram below shows a typical way to separate data and code:
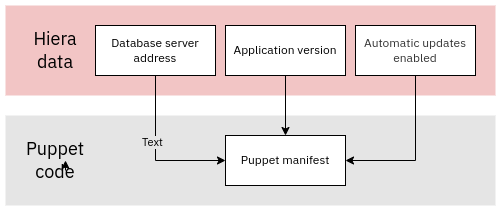
Hiera allows you to have conditional code based on policies (something you decide) or facts (information derived from the node itself). Here are some examples of how Hiera can be used:
- Easily create similar, but slightly different environments (production, staging, development) using the same Puppet code
- Apply code conditionally based on values of facts such as EC2 availability zone, operating system version or the amount of memory on a node
- Enforce stricter security policies on some nodes than on others
While Hiera supports yaml and json backends by default, there a number backend types are available (e.g. hiera-vault and our hiera-tfstate).
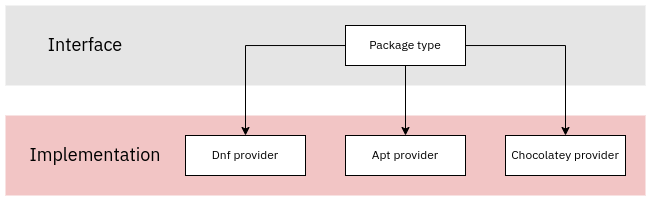
Separation of types and providers
Puppet's types and providers separation makes it easier to adapt the same code to work with different operating systems and deployment options. A good example is the package resource:
package { 'nginx':
ensure => present,
}
What can Puppet manage?
Puppet was originally designed to manage *NIX and Windows systems. As such it is best suited for managing computer systems to which you have root-level access. Puppet is typically used to manage local resources such as
- Packages
- Files
- Services
- Cronjobs
- Mailaliases
- IPtables rules
- Database users
The list of built-in resources is fairly short as of Puppet 6 as many of the core resources were moved to Puppet Forge and are now distributed as Puppet modules. Puppet modules package resources together, which allows you to move the view to a higher level:
- IPtables rulesets
- Timezone settings
- Default local user accounts
- WordPress installations
- Keycloak configurations
- SAML service provider configurations with Apache mod_mellon
A huge number of high-quality modules exist on Puppet Forge and GitHub, including those written by us.
Puppet can also manage services that do not reside on the local computer and are only reachable via an API. For example AWS Cloud resources can be managed with Puppet using the puppetlabs/aws module. That said, Terraform is often a better choice for non-local services because it has a much wider range of providers available.
What Puppet can not manage?
Puppet does not have hard limitations as to what it can or could manage. However, managing Cloud resources for example is not the best use-case for it, whereas Terraform shines in this exact area. There is a logical explanation for that, but it requires understanding the differences in how these two tools operate.
Unlike Terraform Puppet does not use a state file. Instead, Puppet types and providers identify resources they're managing based on their properties. For example, the Package type uses the package name as the identifier. This approach works well for local resources as there's full access to the system Puppet runs on. It works less well Cloud context, mainly because it is not always find uniquely identifiable properties for all Cloud resource types. See the State purpose article on the Terraform website for more information on this topic.
What real-world problems does Puppet solve?
Puppet is at its core a traditional, operating system level configuration management system. As such, it solves all the usual problems with manual system administration.
On top of that different Puppet operating modes solve different problems. Only the main use-cases are covered here:
- Puppet server with agents: policy enforcement, configuration consistency
- Serverless puppet: same as above
- Puppet Bolt: running ad hoc tasks, orchestrating changes, configuration consistency
- Puppet apply: provisioning, image building
If you're primarily concerned with policy enforcement and configuration consistency then a server-agent setup is the correct choice.


