This blog post is a part of this blog post series:
- Puppet types and providers development part 1: creating the type
- Puppet types and providers development part 2: creating a resource
- Puppet types and providers development part 3: on resource uniqueness
- Puppet types and providers development part 4: caching resource properties to improve performance
- Puppet types and providers development part 5: self.instances
- Puppet types and providers development part 6: mysteries of self.prefetch
In the previous blog post we talked about how to identify the resources that are being managed. This post will talk about the various ways of fetching the current state of the resources you wish to manage.
Puppet manages a resource's properties by checking their current state and if the current state differs from the state defined in the Puppet manifest ("desired state") then Puppet will execute the commands necessary to fix the situation. So, when writing a Puppet provider you need to figure out a way to get the current state of all the resources of the type (e.g. file, package, LibreNMS service) you're managing as efficiently as possible.
Before we go any further with our topic, let's lay out the hierarchy of a Puppet type in a graph format:
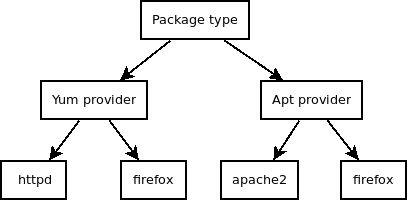
The highest level, type, defines the blueprint for a resource Puppet manages. Below it are providers, each of which implement a specific way for actually managing those resources. At the lowest level are the actual resources being managed. This hierarchy and especially the lowest two levels are important, because they map directly to our provider's Ruby code: the provider is the class and a resource is the instance of that class.
One of the keys to good performance is to minimize the number of actions that are needed to figure out the current state of the resources. Traditionally, and whenever possible, you should use self.prefetch for this. It runs once for each resource provider (e.g. yum in package type) and fetches all properties of the resources (e.g. httpd and firefox) that that provider is responsible for. Then self.prefetch puts those properties into a hash called @property_hash. The property hash can then be used by any instance of the provider (e.g. package called httpd managed by yum) to very quickly figure out if its state has diverged from the desired state. This approach works very well for local resources such as packages where you may have several providers (e.g. apt, gem, yum) but each of them is able to list all the resources they are responsible for.
Where self.prefetch breaks down is management of remote systems. Of course, Puppet was not designed to manage remote systems, but that is what it can and does do quite well. The problem is that you may want to manage multiple remote systems with different URLs, API keys and such. Moreover, if you only had one remote system, you'd still be defining the connection details at the resource (instance) level. If you tried to use self.prefetch you could not target any particular remote system as self.prefetch works on the provider (class) level, runs only once per provider within a Puppet run and does not have access to the parameters of provider instances, that is, the connection details of the individual resources you are managing.
So, when working with remote systems you cannot really use self.prefetch. Optimally you'd prefetch all the properties of all resources that share the same connection details and I'm sure that can be done somehow. But that does not give any performance benefit if you only have one instance of the resource in the catalog, which may be the case if, say, a node managed by Puppet is responsible for adding itself to a monitoring system. It might give a performance boost if each node exported its resource to a central place (e.g. a monitoring server) and all the resources were realized in one place. But exporting the resource adds delay which you may not want. Also, it may be that the remote system does not even have a single API call that allows fetching all the properties for all the resources you're interested in, so you might still need to run one API call for each resource you're managing. In a nutshell "it all depends".
Even if you have to run an API call for each resource instance you can make things suck less. In the worst case you'd have to run an API call for each property in each resource you're managing, but this kind of horror scenario is probably quite rare. In most case you can cache all the properties of each individual resource and reuse those within that provider instance. In librenms_device and librenms_service I (mis)used the exists? method to cache all the properties of the current resource to an instance variable called @my_properties. The exists? method was a natural choice because it runs before any other instance methods and is guaranteed to get executed. This "property hash" of sorts could then be used in the methods that get the property values, instead of having to do yet another API call for each of them.
...

